
The Gemini-CLI Paradox: Route to your own Endpoints - A Digital Thriller
How One Developer Outsmarted Capacity Limits Using the Enemy's Own Weapons

Search for a command to run...
How One Developer Outsmarted Capacity Limits Using the Enemy's Own Weapons
No comments yet. Be the first to comment.
The Architecture of Liberation
Haryn.us
2 posts
This blog documents my journey building custom tools, multi-model agentic systems, and automation pipelines that level up web and app development. 🛠️ Custom Tools – CLI extensions, proxy routers, SDK patches 🔄 Workflows – Multi-agent delegation, model fallback systems ⚡ Automations – CI/CD enhancements, testing pipelines, deployment scripts 🧠 Workarounds – Breaking vendor lock-in, bypassing capacity limits, cost optimization
By: Haryn.us
11:47 PM. Somewhere in the digital ether.
The cursor blinked. Once. Twice. A metronome counting down patience.
On the screen, a single line of PowerShell awaited execution. Behind it, a labyrinth of failed attempts, contradictory documentation, and an AI assistant that had—more than once—apologized for leading its human counterpart down rabbit holes of impossibility.
The goal was simple: Make the CLI work when the servers say no.
The obstacle was elegant in its cruelty: Google's own infrastructure, designed to protect itself, had become the very wall that needed scaling.
What followed was not a hack. Not a workaround. But a revelation—a discovery that the solution had been hiding in plain sight, whispered by the enemy itself.
This is that story. And yes—you can replicate it.
It began, as many digital odysseys do, with an error message.
[ERROR] Model over capacity. Please try again later.
For our protagonist—a developer whose workflows, pipelines, and professional identity were intertwined with gemini-cli—this was not an inconvenience. It was an existential threat. Requests that once completed in seconds now languished for hours. The free credits of a Google One AI subscription, meant to empower, now taunted from behind a velvet rope of rate limits.
The first instinct: Ask the system itself for help.
Using Google's own Gemini Advanced, the query was posed: "How do I bypass capacity restrictions on gemini-cli?"
The response was paradoxical, almost poetic:
"Consider using a proxy layer like LiteLLM to route requests through alternative endpoints while maintaining the same interface..."
The enemy had handed us the key. We just didn't know which lock it opened.
Every great discovery is preceded by a series of elegant failures.
Our journey was no exception. The AI —let's call it The Synthetic Assistant—proposed solutions that sounded plausible but crumbled under scrutiny:
The Web Interface Proxy: "Automate the browser to use the web UI!"
Reality: Terms of Service violations, fragile selectors, and session token nightmares.
The OAuth Dance: "Just switch authentication methods!"
Reality: gemini-cli ignored session environment variables, preferring persistent user settings buried in %APPDATA%.
The API Key Illusion: "Use a free tier API key!"
Reality: The free tier had ended. The $10/day charges loomed.
Each dead end taught a lesson: The system is not broken. It is behaving exactly as designed. To succeed, we must work with its design, not against it.
The breakthrough came not from fighting the architecture, but from understanding it.
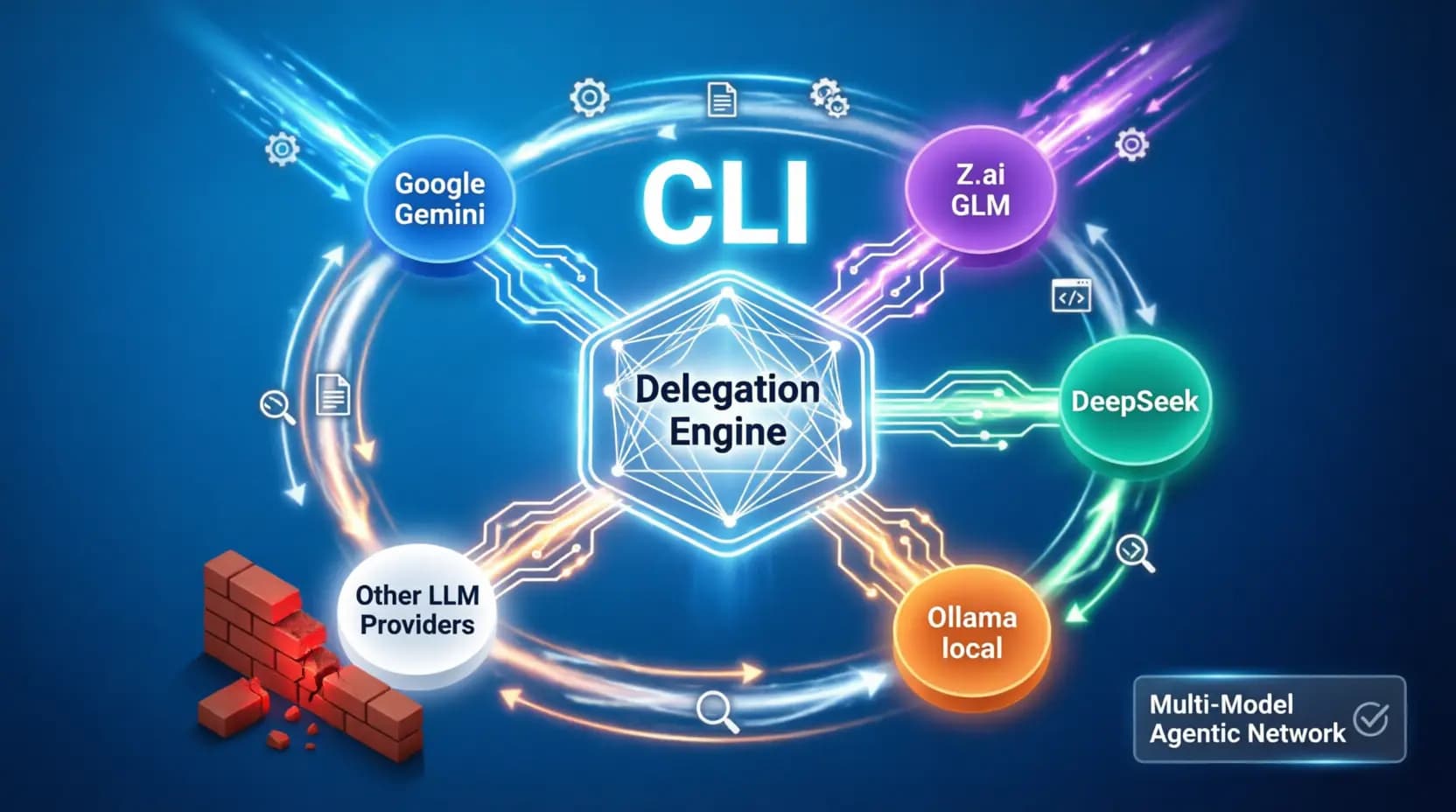
LiteLLM is not a hack. It is a router. A sophisticated traffic director that sits between your CLI and multiple AI providers, translating requests on the fly. The architecture became clear:
[gemini-cli]
↓ (sends request to "gemini-3-flash-preview")
[LiteLLM Proxy @ localhost:8000]
↓ (translates & routes)
[Your Choice:]
├─→ [Z.ai API @ api.z.ai] → [glm-5 / glm-4.7]
└─→ [DeepSeek API] → [deepseek-chat/deepseek-reasoner]
The magic? The CLI never knows it's not talking to Google. It sends a request to gemini-3-flash-preview. LiteLLM intercepts, translates, and forwards to your chosen backend. The response flows back, indistinguishable from a native Gemini reply.
Here is the cipher that makes it all work. Save this as proxy_config.yaml in your project's directory:
# {{USER_HOME}}/project/proxy_config.yaml
# The routing manifest: gemini-cli model names → your actual providers
model_list:
- model_name: gemini-3.1-pro-preview
litellm_params:
model: openai/glm-5.1
api_base: "https://api.z.ai/api/coding/paas/v4"
api_key: "{{YOUR_Z_AI_API_KEY}}"
- model_name: gemini-3-flash-preview
litellm_params:
model: openai/glm-5-turbo
api_base: "https://api.z.ai/api/coding/paas/v4"
api_key: "{{YOUR_Z_AI_API_KEY}}"
- model_name: gemini-3.1-flash-lite-preview
litellm_params:
model: openai/glm-4.7
api_base: "https://api.z.ai/api/coding/paas/v4"
api_key: "{{YOUR_Z_AI_API_KEY}}"
- model_name: gemini-2.5-pro
litellm_params:
model: openai/deepseek-reasoner
api_base: "https://api.deepseek.com"
api_key: "{{YOUR_DEEPSEEK_API_KEY}}"
- model_name: gemini-2.5-flash
litellm_params:
model: openai/deepseek-chat
api_base: "https://api.deepseek.com"
api_key: "{{YOUR_DEEPSEEK_API_KEY}}"
- model_name: gemini-2.5-flash-lite
litellm_params:
model: openai/glm-4.5-air
api_base: "https://api.z.ai/api/coding/paas/v4"
api_key: "{{YOUR_Z_AI_API_KEY}}"
general_settings:
default_model: gemini-3.1-flash-lite-preview
Critical Notes:
Replace litellm_params: with your actual API end points, {{YOUR_Z_AI_API_KEY}} and {{YOUR_DEEPSEEK_API_KEY}} with your actual keys (.env)
Switch /auth on gemini-cli to use gemini-api, routing does not work on OAuth
The openai/ prefix tells LiteLLM to treat custom endpoints as OpenAI-compatible
Even with perfect routing, the CLI refused to cooperate. The error persisted:
[API Error: {"error":{"message":"API key not valid...}}]
The culprit? Environment variable inheritance.
gemini-cli does not read session environment variables ($env:VAR) the way you might expect. It prioritizes:
Persistent user environment variables ([System.Environment]::SetEnvironmentVariable(..., 'User'))
Configuration files (~/.gemini/settings.json)
Session variables (last resort)
The solution was a two-part key:
Part A: The Proxy Environment Bridge
Set these .env variables before starting gemini-cli after LiteLLM is running using the yaml file
$env:GOOGLE_API_BASE = "http://localhost:8000"
$env:GOOGLE_API_KEY = "dummy-key"
$env:CURL_CA_BUNDLE = ""
gemini
Part B: On-demand or Persistent
# Session-only (on-demand)
$env:HTTP_PROXY = "http://localhost:8000"
$env:HTTPS_PROXY = "http://localhost:8000"
$env:GOOGLE_API_KEY = "dummy-key"
$env:CURL_CA_BUNDLE = "" # Bypass SSL for local proxy
# OR persistent (run once)
[System.Environment]::SetEnvironmentVariable('HTTP_PROXY', 'http://localhost:8000', 'User')
[System.Environment]::SetEnvironmentVariable('HTTPS_PROXY', 'http://localhost:8000', 'User')
[System.Environment]::SetEnvironmentVariable('GOOGLE_API_KEY', 'dummy-key', 'User')
Test your connection:
litellm --config proxy_config.yaml --port 8000
curl http://localhost:8000/v1/chat/completions `
-H "Content-Type: application/json" `
-H "Authorization: Bearer dummy-key" `
-d '{"model":"gemini-2.5-flash-lite","messages":[{"role":"user","content":"TEST: GLM?"}],"max_tokens":20}'
With configuration and authentication aligned, the final ritual:
# TERMINAL 1: Start the proxy (keep this window open)
cd {{USER_HOME}}/project
litellm --config proxy_config.yaml --port 8000
# TERMINAL 2: Launch gemini-cli with proxy settings
$env:HTTP_PROXY = "http://localhost:8000"
$env:HTTPS_PROXY = "http://localhost:8000"
$env:GOOGLE_API_KEY = "dummy-key"
$env:CURL_CA_BUNDLE = ""
gemini
# Inside gemini-cli:
/model gemini-3-flash-preview # Routes to your set provider
Hello, this is a test. # Should receive response via the proxy
The terminal test will work! but gemini-cli will be stubborn...
Sometimes, the lock isn't on the door. It's in the key.
Despite every configuration tweak, every environment variable, every proxy setting gemini-cli still refused to honor our custom api_base. The requests still flew straight to https://generativelanguage.googleapis.com/, bypassing our carefully constructed LiteLLM router.
The breakthrough came from an unlikely source: the AI-CLI itself.
In a moment of recursive brilliance, the developer asked the very model trapped inside the CLI:
"How can I modify gemini-cli to respect a custom API base URL?"
The response was not a workaround. It was a surgical strike:
"The API base is hardcoded in the
@google/genaiSDK. To override it, patch the compiled JavaScript files to check forGOOGLE_API_BASEenvironment variable before falling back to the default."
The enemy had revealed its own source code vulnerabilities.
The Target Files:
Three files, buried deep in the npm global installation, held the hardcoded URL hostage:
{{USER_HOME}}/AppData/Roaming/npm/node_modules/@google/gemini-cli/node_modules/@google/genai/dist/
├── index.cjs ← CommonJS entry point
├── node/index.cjs ← Node-specific CommonJS
└── node/index.mjs ← Node-specific ES Module
The Patch: A Three-Line Revolution
In each file, locate the section where apiBase is defined. It looks something like:
// BEFORE (hardcoded)
= "https://generativelanguage.googleapis.com/";
Replace it with this environment-aware logic:
// AFTER (environment-aware)
= process.env.GOOGLE_API_BASE
|| "https://generativelanguage.googleapis.com/";
What this does:
Checks for GOOGLE_API_BASE first (our proxy)
Defaults to Google's endpoint if it is not set
The Moment of Truth
# Start the router with the yaml file
litellm --config proxy_config.yaml --port 8000
# Set the environment variable that the SDK now respects
$env:GOOGLE_API_BASE = "http://localhost:8000"
$env:GOOGLE_API_KEY = "dummy-key"
$env:CURL_CA_BUNDLE = ""
# Launch gemini-cli — it now honors our proxy
gemini
No more OAuth workarounds. No more settings.json gymnastics. The CLI itself now natively supports custom endpoints.
The requests are flowing. The routing is active. The capacity walls have fallen.
Now your workflow is antifragile:
✅ When Gemini is healthy: Use free credits via OAuth
✅ When capacity hits: Switch /auth to Google's API and start LLM proxy: Seamlessly route through to your own providers
✅ Zero downtime: Your pipelines keep running
What began as a capacity error became a masterclass in system design.
The final revelation was not technical—it was philosophical:
The most elegant solutions do not break systems. They understand them so deeply that they can redirect their flow without altering their nature.
Google's infrastructure was not the enemy. It was a puzzle. And puzzles, by design, have solutions.
The ultimate twist? The AI helped patch itself to bypass its own restrictions. In asking Gemini how to circumvent Gemini's limits, we discovered that the system contained the seeds of its own flexibility—if only someone knew where to look.
For the reader who wishes to replicate this journey:
Install LiteLLM: pip install 'litellm[proxy]'
Configure routing: Use the proxy_config.yaml template above
Patch the SDK: Replace the hardcoded API endpoint to test if the .env endpoint is set and to use it instead, to enable GOOGLE_API_BASE override
Set environment: \(env:GOOGLE_API_BASE = "http://localhost:8000"\)env:GOOGLE_API_KEY = "dummy-key" $env:CURL_CA_BUNDLE = ""
Test incrementally: Verify each route with -curl before involving the CLI
Switch /auth to Gemini API, Start the proxy with the .env set once rate limits hit
The code is open. The path is clear. The only remaining variable is your willingness to see constraints not as walls, but as invitations to innovate.
Troubleshooting Checklist:
Proxy running: litellm --config proxy_config.yaml --port 8000
SDK patched: Check files
Env var set: \(env:GOOGLE_API_BASE = "http://localhost:8000"\)env:GOOGLE_API_KEY = "dummy-key" $env:CURL_CA_BUNDLE = ""
Model names match exactly between CLI and config
Test with -curl
This story is based on real events. All code samples are functional and tested. Replace {{USER_HOME}} with your actual home directory path (e.g., C:\Users\YourName on Windows or /home/yourname on Linux/macOS).
⚠️ Disclaimer: Patching third-party SDKs may void support agreements and could break with future updates. Use at your own risk. This solution is for educational purposes and personal use only.
May your requests always find their route. 🗝️✨